Evolution from RDBMS to NoSQL
A close look at the evolution of database over time highlights that we have come a long way in terms of how we manage data. More than anything, our needs have also evolved with time. With that, “What we store” has also become a matter of prime importance. The “type of data to store” has also changed. In fact, the definition of data itself has changed over time. The randomness in data has grown exponentially in contrast to 10 years back when data was “structured” and could easily be stored and modeled in tabular relation (Relational Database or RDBMS).
Why NoSQL Database?
Think of an e-commerce website that stores all the user information with the purchase history. Ten years back, these would not have been useful data at all (just saying). But, in today’s competetion, with analytics and customer personalization in focus, these data have a huge value in market. In fact, it is a key contributing factor to the profit incurred by your organization. Such data are available as a result of different applications generating millions of documents. And these are not stored in one place. Though we can still normalize these data in a predefined structure, but we miss out on a lot of information as a part of doing so. And of course, it is a pain to store all these data in a tabular or structured format in RDBMS.
NoSQL provides a mechanism for storage and retrieval of structured, semi-structured, unstructured or polymorphic data. It encompasses a wide variety of different database technologies that were developed in response to the demands presented in building modern applications:
> Developers are working on applications that creates huge volume of data with rapidly changing data types
> Teams are working in Agile Sprints and pushing in code every now and then
> Applications (that were once monolithic) are being broken down into smaller modules and served as service with high availability
> In order to cater to the huge traffic efficiently, Organizations are turning towards scaling out architecture using open source technologies on cloud in contrast to large data centers running on expensive hardwares.
Relational databases were not created keeping in mind the agility and scaling challenges faced by modern applications. However, there are solutions available. But these problems can be addressed more easily by a NoSQL database.
Having said all that, NoSQL databases have their own set of disadvantages too. And, while it may sound like Relational Databases are outdated and dead, that would be a false assumption to make as they are still very much in the game.
Scaling and Sharding
Standard definitions say :
Scalability is the capability of a system, network, or process to handle a growing amount of work, or its potential to be enlarged in order to accommodate that growth.
The way RDBMS is designed, it can only be scaled vertically, meaning a single server must be made increasingly powerful in order to deal with increasing demand. On the other hand, NoSQL database can be scaled horizontally, meaning that to add capacity, a database administrator can simply add more commodity servers or cloud instances. The database automatically spreads data across servers as necessary.
“Sharding is a type of database partitioning that separates very large databases the into smaller, faster, more easily managed parts called data shards. The word shard means a small part of a whole.“
Sharding and scaling are closely related. In sharding, we can break a large chunk of data (say 100MB) into smaller chunks (say 10MB) and can store them independently across servers (with multiple replications for redundancy).
Lets, see an example. We want to store a document of 40 MB in our NoSQL database. Let’s assume, that we agreed to divide it into four smaller blocks of 10 MB each and store them independently in four different geographic locations where our servers are deployed (with a NoSQL database running in them). Each of these logically isolated data are called “Shards” (Refer to the diagram below). However, it doesn’t always need to be in discrete geographic locations, as in this case. In fact, all your shards can run on only one single piece of hardware.
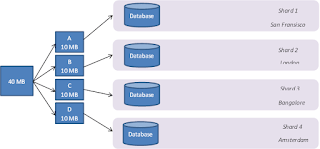
With time, of course, our database will increase in volume. In such a case, when our database is almost full, we can go ahead and add additional shards. This way, NoSQL can guarantees horizontal scaling.
What about Redundancy?
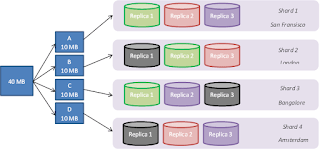
So far, so good! But what if our server deployed in (say) London fails/crashes? So, we need to build data redundancy. And who is going to take care of this? Of course, our database! So, we have multiple replicas of the same database in different servers of each shard. These are known as “Replica sets“. Ideally, each replica set should be in different data centers or zones (if you are on cloud), so that, if somehow one data center goes down, we can still have our backup in other replicas running somewhere else.
In order to understand this, we will color code each Replica set (with three replica nodes each e.g. 1,2,3) in different colors:
Green Replica Set
Pink Replica Set
Grey Replica Set
Purple Replica Set
Let’s refer to the new diagram. We have block A stored in Shard 1, that is in San Francisco. But we don’t know which replica set. And we don’t even need to know. It is known that if it is in Shard 1, the data is store in either Green or Pink or Purple. Rest assured, each of these replica set have a copy of exactly the same data in other Shards too. Example, say block A gets stored in Green Replica set. Now, another replica of the same block is stored in Shard 2 in London, and another in Shard 3, Bangalore. This way, even if the database goes down in London, we can still ensure that it can be recovered back from the other shards without any interruption. And the front end consumer won’t even know which node/server is serving the data. We can have any level of replication, based on our choice/requirement. However, it is a standard practice to have a replication factor of 3.
NoSQL Vs RDBMS
So, how to choose between RDBMS and NoSQL? The answer to this question is obviously context dependent. It all depends on what your application does and how?
Say, I created an inventory system for managing the usage of telecom devices by it’s subscribers. Now, if I need to find out how many hours was spent by one of the subscribers in December, last year, I need to work with huge volumes of unstructured data (stored as log files) and find the answer. In this situation, it makes more sense to use a NoSQL database like Mongodb.
One important thing to keep in mind is that, there is a fair bit of latency involved while querying NoSQL database (the latency being directly proportional to the unstructured data). Obviously, there are caching mechanisms to resolve that.

On the other hand, consider that I have a requirement of creating a payroll software for an organization with thousand employees. Obviously the employees would be managed in a certain hierarchy with multiple systems linked to each other like employee’s bank account, personal details, work schedule. While working with such a related system, any RDBMS would be an obvious choice. Relational databases are comparatively faster as it iterates through similar structured data.

What did we see & what we learnt?
There is no one solution that solves all kind of problems and can be implemented in the same way. If our application is data heavy and involves working with huge chunks of data, we have NoSQL whereas on the other hand if our application involves working data that are logically related and are properly structured (that can be modeled as a schema/table), we use RDBMS.
